

Davinci Resolveはバージョン18.5から自動音声テキスト化機能が搭載されたそうですが、音声認識モデルを自分で選んで使いたい人向けにシステムを考えてみました。
実装例として想定している環境は下記のような感じです。
OS : Windows
Davinci Resolve 18.6
VRAM : 4-5GB (CUDA 11.8)
オールインワンシステムでもいいのですが、ブログに書きずらいので下図のように分割して考えてみます。
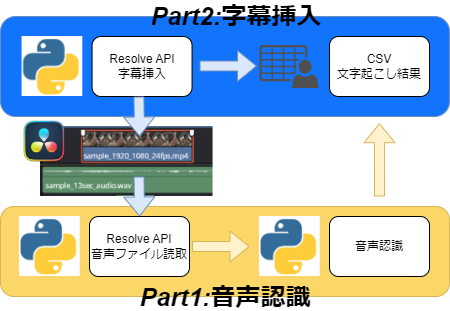
以下はシステム全体のざっくりした処理説明
Part1
– DaVinchiResolveのオーディオトラック上にあるファイルを読み込む
– 音声認識モデルへデータを渡す
– 認識結果をCSVファイルへ書き込み
Part2
– 音声認識結果のCSVを読み込む
– 字幕の挿入位置と挿入文字をDaVinchiのビデオトラックへ挿入
今回はPart0で開発環境を整えます。
Step1
DaVinchi Resolveでpython apiを使えるようにします。
Pythonのパスさえ通っていればバージョン18.6では特に何もしなくてもConsoleにPrint(resolve)と打つと値が帰ってくるので必要ないかもしれませんが、もしエラーが帰ってくる場合、ちょっと古いですが下記の記事を参考にして入れてみてください。
[DaVinci ResolveのPython api環境構築]
音声データの読取りは以前紹介した方法でデータを読んでいこうと思います。
[DaVinci Resolveで元素材のカット・トリミングした時間を確認する]
Step2
使いたい音声認識モデルを変更するつもりがなければDaVinchi Resolveが参照しているpythonインストール環境で構築しても良いですが今回は別途anacondaで音声認識環境を作ります。
ここで好きな音声認識モデルを使う為に頑張っているわけなので特に指定はありませんが、今回はReazonSpeechを使う前提で実装していきます。
まずは説明用に仮想環境をdavinchi-voiceとして作成します。
conda create -n davinchi-voice python=3.11 anaconda後は環境をアクティベートしてPyTroch2.2.1をインストールします。(PyTorchダウンロードページ)
インストール方法は下記の記事通りに入れています。
[ReazonSpeech v2をWindowsローカル環境で動かす]
音声認識モデルによりますが、ある程度の長さの発話区間で区切ってデータを渡したいのでSilero VADという発話区間認識モデルもシステムに取り入れたいと思います。
こちらもインストール方法は下記の記事通りに入れています。
フォルダ構成
音声認識モデル:”ReazonSpeechをcloneした所”\model\reazonspeech-nemo-v2.nemo
発話区間検知モデル:C:\Users\自分\.cache\torch\hub\snakers4_silero-vad_master\files\silero_vad.jit
DaVinchiディレクトリ:C:\ProgramData\Blackmagic Design\DaVinci Resolve\Fusion\Scripts\Utility
Utility/
├ my_auto_subtitle_insert.py [TLへの字幕挿入用]
└ my_auto_subtitle_start_process.py [TLの音声データ取得用]
音声認識スクリプトディレクトリ:”好きな所”\voice_recognition
voice_recognition/
├ davinchi_voice_recognition.py [音声->文字用]
├ utils_vad.py [silero vadのgitリポジトリからダウンロードしてコピー]
└ result_data/ [認識結果保存用]


