

前回は開発環境構築をしたので、今回はDaVinchi ResolveのオーディオTLから音声ファイルを読み取るところをやってみたいと思います。
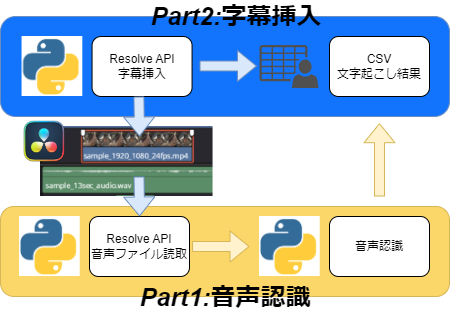
上図のPart1をもうちょっと真面目に考えると下図のようなイメージです。
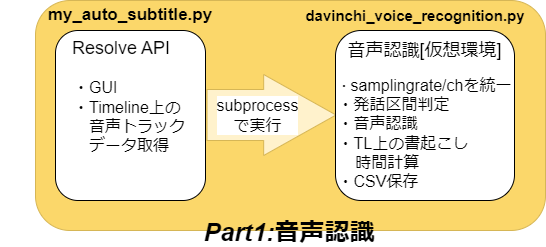
今回はGUIのapiを使う部分を書いていこうと思います
my_auto_subtitle.py
Resolve apiを使った処理部分です。
GUIのapiは解説が無かったのですが、Webでまとめられていました。[https://resolvedevdoc.readthedocs.io/en/latest/index.html]
GUIを作成
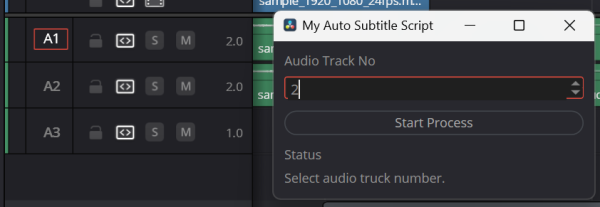
GUIにやらせたいのは下記3点。
- 処理するオーディオトラックの番号指定
- 処理スタートボタン
- ステータス表示
GUIのガワはdispatcher.AddWindow関数で定義し、GUIの各アイテム(ボタンやラベル)のイベント処理はアイテムの属性に自作関数を入れていくスタンダードな方法で使えます。
def main_UI():
# UI api
ui = fusion.UIManager
dispatcher = bmd.UIDispatcher(ui)
# Window layout setting
win = dispatcher.AddWindow(
{ 'ID': "myWindow",
'WindowTitle': 'My Auto Subtitle Script',
'Geometry': [200,150,300,300] },
ui.VGroup([
ui.Label({ 'Text': 'Audio Track No' }),
ui.SpinBox({ 'ID': 'AudioTrack', 'Value': 1, 'Minimum': 1, 'Maximum': 10}),
ui.VGap(0, 10),
ui.Button({ 'ID': "StartButton", 'Text': "Start Process"}),
ui.VGap(0, 10),
ui.Label({ 'Text': 'Status' }),
ui.Label({ 'ID': 'Status', 'Text': 'Select audio truck number.' })
])
)
def OnButtonClicked(ev):
button = win.Find('StartButton')
button.Enabled = False
button.Text = 'Now processing...'
track_id = win.Find('AudioTrack').Value
audio_process(int(track_id), win.Find('Status'))
button.Enabled = True
button.Text = 'Start Process'
def OnClose(ev):
dispatcher.ExitLoop()
# Assign events
win.On['StartButton'].Clicked = OnButtonClicked
win.On.myWindow.Close = OnClose
win.Show()
dispatcher.RunLoop()機能としてはトラックの番号を選んで”Start Process”ボタンが押されたらaudio_process関数に全投げするようにしています。
実装に成功すると下図のようなwindowをapiが生成します。
audio_process関数は選択されたトラック番号とステータス表示用のラベル要素を貰って、残りの機能をそれぞれの関数にぶん投げています。
- get_timeline_audio_data : 選択トラック内のデータ収集関数
- voice_recognition : 音声認識ようのスクリプトを叩く関数
def audio_process(idx, status_label):
status_label.Text = 'Reading timeline audio data'
tl_audio_data = get_timeline_audio_data(idx)
status_label.Text = 'Loading voice recognition model. Takes long time \n'
voice_recognition(tl_audio_data, status_label)
トラック内のデータ収集:get_timeline_audio_data
実装内容は以前のDaVinci Resolveで元素材のカット・トリミングした時間を確認するとほぼ同じ内容なので割愛します。
データの収集内容は
- TL上にあるオーディオのフレーム位置[開始フレーム&終了フレーム]
- デフォルトだとスタートフレームは1時間からなので3600sec×フレームレート
- オーディオの素材パス
- オーディオ素材の元のフレームレート
- トリミングしたフレーム位置[開始&終了]
def get_timeline_audio_data(idx):
# Timeline情報の取得
project_manager = resolve.GetProjectManager()
project = project_manager.GetCurrentProject()
timeline = project.GetCurrentTimeline()
# A1 Timeline上にあるアイテムの取得
clip_audio_timeline_items = timeline.GetItemListInTrack("audio", idx)
result = {}
for idx, item in enumerate(clip_audio_timeline_items):
audio_item = {}
audio_item['id'] = idx + 1
# TL上のframe位置
audio_item['tl_position_start'] = item.GetStart()
audio_item['tl_position_end'] = item.GetStart()
# 素材情報
media_item = item.GetMediaPoolItem()
audio_item['file_path'] = media_item.GetClipProperty("File Path")
audio_item['fps'] = media_item.GetClipProperty("FPS")
# 前からトリミングした位置 Left, 後ろからトリミングした位置 Right
audio_item['clip_start'] = item.GetLeftOffset()
audio_item['clip_end'] = item.GetRightOffset()
result[str(idx)] = audio_item
return result
収集したデータをsubprocessで送信:voice_recognition
一番めんどくさい処理なのでsubprocessで雑に作りました。
起動したいanacondaの仮想環境フォルダにあるpython.exeと音声認識スクリプトがある作業フォルダを指定し、get_timeline_audio_dataで取得した情報を文字列展開しコマンド実行。
実行後は音声認識モデルの読み込みや処理で長時間応答がないので、process.stdout.readline()で標準出力を取得して処理内容がわかるようにGUIラベルに表示させています。
import subprocess
import time
import json
anaconda_env_path = 'C://Users//自分//anaconda3//envs//ytube//python.exe'
voice_recognition_path = '作業フォルダパス//davinchi_voice_recognition.py'
def voice_recognition(audio_data, status_label):
send_data = json.dumps(audio_data)
command = [anaconda_env_path, voice_recognition_path, send_data]
process = subprocess.Popen(command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True)
while True:
output_line = process.stdout.readline()
if output_line:
print(output_line.strip()
status_label.Text = output_line.strip()
if not output_line and process.poll() is not None:
break
time.sleep(0.1)
process.wait()
status_label.Text = "Finish voice recognition \n"
