

whisperやrinnaなどの重い音声認識処理をする前に、サウンドファイル内で発話部分のみを抜き取る軽い処理を挟みたい時があります。
調べた時点ですぐに実装出来そうな雰囲気のものは下記の5つぐらい。
- N cross法 (python) | Qiita
- 音声有効区間とモーラの検出 (Python) | Qiita
- py-webrtcvad | github
- inaSpeechSegmenter | github
- silero-vad | github
今回は手持ちの音声ファイルと相性が良かったSilero VADを使ってみたのですが、インストール内容以外の日本語記事が少なかったので使い方について書いてみました。
想定環境はWindowsです。
インストール
公式に従いライブラリをインストール
- pytorch >= 1.12.0 | 今回は2.2.1+cu118を使用
- torchaudio >= 0.9.0 | 今回は2.2.1+cu118を使用
モデルのダウンロードはpythnコードで実行。
(手動で直接モデルをDLする場合はここから。)
import torch
# download example
torch.hub.download_url_to_file('https://models.silero.ai/vad_models/en.wav', 'en_example.wav')上記を実行すると下記のフォルダに2つのモデルがダウンロードされます。
“C:\Users\自分\.cache\torch\hub\snakers4_silero-vad_master\files”
- jitモデル : silero_vad.jit
- ONNXモデル : silero_vad.onnx
モデルの違いは公式によると、ONNXモデルの方がファイルが重い分処理が4-5倍速い可能性があります。
どちらのモデルもCPU1スレッドで動作させるパフォーマンスに最適化されていて既に量子化済みです。
今回は軽さ重視でjitモデルを使用していきます。
utils_vad.pyの使い方
公式通りダウンロードすると下記のフォルダに一式コードが保存されています。
- “C:\Users\自分\.cache\torch\hub\snakers4_silero-vad_master”
手動でモデルをダウンロードした場合は下記からutils_vad.pyを持ってきます。
以降は実行ファイルでutils_vadを読み込んで使用することを想定しています。
モデルのロード
import torch
torch.set_num_threads(1)
from utils_vad import init_jit_model
# jitモデルのロード
model = init_jit_model(os.path.join('<pass to download model>', 'silero_vad.jit'))
ファイルの読み込み
import torch
torch.set_num_threads(1)
from utils_vad import read_audio
SAMPLING_RATE = 16000
wav = read_audio('test.wav', sampling_rate=SAMPLING_RATE)変数wavはtorch.Tensor型です。
入力ファイルのサンプリングレートは8kHzか16kHzのみなので44.1kHzの場合はffmpegなどでサンプリングレートを下げてから入れる必要があります。
# cmd サンプリングレート変更サンプルコマンド
ffmpeg -i teset.wav -ar 16000 output.wav
検出
import torch
torch.set_num_threads(1)
from utils_vad import get_speech_timestamps
SAMPLING_RATE = 16000
# 変数modelはinit_jit_modelメソッドで取得済みとする
# 変数wavはread_audioメソッドで取得済みとする
speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=SAMPLING_RATE, return_seconds=True)処理が終わると変数speech_timestampsに発話したファイル内での秒数が保存されます。
フォーマットは下記のような感じで、startとendキーを持つ辞書要素のリスト配列が帰ってきます。
[{‘start’: 1, ‘end’: 2}, {‘start’: 5, ‘end’: 8}…]
検出の進捗表示
import torch
torch.set_num_threads(1)
from utils_vad import get_speech_timestamps
from tqdm import tqdm
SAMPLING_RATE = 16000
pbar = None
def my_progress_update(progress):
# tqdmを使わない場合は単にprogress値を表示
# print(f"Progress: {progress}%")
# tqdmを使う場合
if (pbar is None):
pbar = tqdm()
pbar.update(progress - pbar.n)
# 変数modelはinit_jit_modelメソッドで取得済みとする
# 変数wavはread_audioメソッドで取得済みとする
speech_timestamps = get_speech_timestamps( wav, model,
sampling_rate=SAMPLING_RATE,
progress_tracking_callback=my_progress_update)get_speech_timestampsメソッドのprogress_tracking_callbackに関数を入れるとコールバックしてくれるので進捗率を取得出来ます。
検出区間の保存
保存時はタイムスタンプを秒数ではなくサンプルで取得(return_seconds=Trueを消す)
import torch
torch.set_num_threads(1)
from utils_vad import (get_speech_timestamps, collect_chunks, drop_chunks)
SAMPLING_RATE = 16000
# 変数modelはinit_jit_modelメソッドで取得済みとする
# 変数wavはread_audioメソッドで取得済みとする
speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=SAMPLING_RATE)
####################################
# 発話区間をまとめて一つのファイルにする
####################################
save_data = collect_chunks(speech_timestamps ,wav)
save_audio('save.wav', save_data)
####################################
# 発話区間を一つづつ別のファイルにする
####################################
for idx, time_stamp in enumerate(speech_timestamps):
chunk = collect_chunks(time_stamp, wav)
save_audio(str(idx)+'_save.wav', chunk)
####################################
# 発話区間を削除したファイルを1つにまとめる
####################################
delete_data = drop_chunks(speech_timestamps ,wav)
save_audio('save.wav', delete_data)
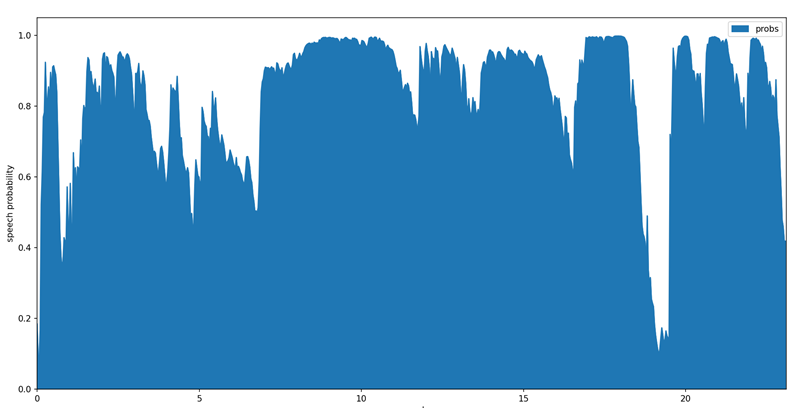
発話区間の可視化
pandasとmatplotlibのライブラリがインストールされている場合、発話区間の確率をグラフ表示出来ます。
import torch
torch.set_num_threads(1)
from utils_vad import (get_speech_timestamps)
import matplotlib.pyplot as plt
SAMPLING_RATE = 16000
# 変数modelはinit_jit_modelメソッドで取得済みとする
# 変数wavはread_audioメソッドで取得済みとする
speech_timestamps = get_speech_timestamps(wav, model,
sampling_rate=SAMPLING_RATE,
visualize_probs=True)
plt.show()サンプルグラフ
stream処理
公式のStream imitation exampleの最初のコード、”## using VADIterator class”は0.032 sec (= 512/16000)毎に発話区間の判定をしていきます。
“## just probabilities”のコードは0.032 sec毎に発話確率を返します。

