

第三回目です。次で終わりにしたい…
[前回:無料版Davinchi Resolveで字幕生成システムを作る #2 | GUIのapiを使う]
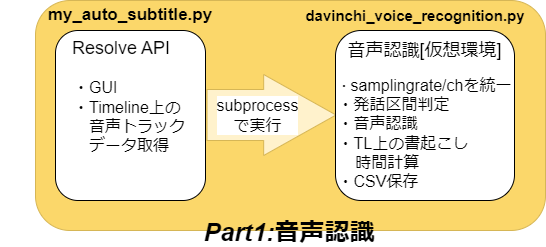
davinchi_voice_recognition.pyを実装していきます。
davinchi_voice_recognition.py
音声認識の処理を行う本体です。
データの取得
前回作成したmy_auto_subtitle.pyから辞書型オブジェクトを文字列にして引数を貰うので、ここで元に戻します。
データにパスが含まれているので、replaceでいい感じに置換します。(OSにより違うかもしれませんが…)
receive_data = sys.argv[1]
receive_data = receive_data.replace('\\\\','//')
tl_data = json.loads(receive_data)
素材のサンプリングレートとチャンネルを統一
SileroVADの制約により、音声素材のファイルを16-bit PCM/monoチャンネル/16000Hzに変換します。
from pydub import AudioSegment
# Parameters
AUDIO_TIMELINE_PATH = './result_data/audio_timeline_data.csv'
SAVE_PATH ='C://Users//wapra//Home//workspace//DaVinchiResolve//voice_recognition//result_data//'
BIT_FORMAT = 2 # Audio format (16-bit PCM)
CHANNELS = 1 # Mono audio
SAMPLING_RATE = 16000 # Sample rate
def transform_audio_for_speech_rec(file_path):
audio = AudioSegment.from_file(file_path)
# チャンネル数が2の場合はモノに変換
ch = audio.channels
if ch != CHANNELS:
audio = audio.set_channels(CHANNELS)
print('change to mono audio')
# サンプル幅16ビット(2バイト)に変換
sw = audio.sample_width
if sw != BIT_FORMAT:
audio = audio.set_sample_width(2)
print('change audio bit format')
# サンプリングレートの修正
sr = audio.frame_rate
if sr != SAMPLING_RATE:
audio = audio.set_frame_rate(SAMPLING_RATE)
print('change sr')
# for audio transform test
# audio.export(SAVE_PATH + '//temp//temp.wav', format='wav')
return audio
発話区間判定
取得した音声ファイルをpyTorchのテンソルに変換し、DaVinchi ResolveのTLで切り取られた部分のみを素材から抜き出します。
抜き出したデータをSileroVADへ渡して、発話区間のデータを取得します。
# 発話区間判定
def get_voice_activity_time(audio_tensor):
speech_timestamps = get_speech_timestamps(audio_tensor.float(), vad_model, sampling_rate=SAMPLING_RATE, threshold=0.4)
speech_sound_list = []
for idx,st in enumerate(speech_timestamps):
chunk = audio_tensor[int(st['start']) : int(st['end'])]
speech_sound_list.append(chunk)
# for sound data check
# save_audio(SAVE_PATH + str(idx)+'_save.wav', chunk)
return speech_sound_list, speech_timestamps
# オーディオデータフォーマット変換
audio = transform_audio_for_speech_rec(tl_data[idx]['file_path'])
# オーディオデータをNumPy配列に変換する
samples = np.array(audio.get_array_of_samples())
# データをint16のままテンソルに変換
audio_tensor = torch.from_numpy(samples).type(torch.int16)
# davinchi resolveのTL上でクロップされた部分のみ取り出し
audio_start = int(tl_data[idx]['clip_start'] / tl_data[idx]['fps'] * SAMPLING_RATE)
audio_end = int(tl_data[idx]['clip_end'] / tl_data[idx]['fps'] * SAMPLING_RATE)
audio_tensor = audio_tensor[audio_start : audio_end]
# 発話区間のチェック
speech_sound_list, speech_timestamps = get_voice_activity_time(audio_tensor)
音声認識と字幕用にTL上の書き起こし時間を計算
音声認識は発話区間のみで切り取った音声データをtranscribe関数に入れるだけ。
後は字幕挿入の為に、発話開始時刻と発話時間の長さをひたすら計算しています。
このファイルの最後にresult_dataの中身をファイルへ吐き出して完了です。
for speech_sound, speech_time in zip(speech_sound_list, speech_timestamps):
audio = audio_from_tensor(speech_sound, SAMPLING_RATE)
subtitle = transcribe(recognision_model, audio).text
print(subtitle)
# 発言時間の計算
speech_start_frame = int(tl_data[idx]['tl_position_start']) + int((speech_time['start']/SAMPLING_RATE)*tl_data[idx]['fps'])
speech_duration = (speech_time['end'] - speech_time['start'])/SAMPLING_RATE
result_data.append(str(speech_start_frame) + ',' + str(speech_duration) + ',' + subtitle)
コード全体
import os
import sys
import glob
import json
import csv
import torch
import numpy as np
from pydub import AudioSegment
print('loading voice recognition model')
# for ReazonSpeech
sys.path.append('このスクリプトのある作業ディレクトリ')
from reazonspeech.nemo.asr import load_model, transcribe, audio_from_tensor
from nemo.collections.asr.models import EncDecRNNTBPEModel
recognision_model = load_model(device='cuda')
# for silero vad
vad_model_dir = 'モデルの保存場所'
from utils_vad import (init_jit_model,
get_speech_timestamps,
save_audio,
collect_chunks)
vad_model = init_jit_model(os.path.join(vad_model_dir, 'silero_vad.jit'))
print('finish loading modules')
# Parameters
SAVE_PATH ='音声認識結果の保存ディレクトリ'
BIT_FORMAT = 2 # Audio format (16-bit PCM)
CHANNELS = 1 # Mono audio
SAMPLING_RATE = 16000 # Sample rate
def transform_audio_for_speech_rec(file_path):
audio = AudioSegment.from_file(file_path)
# チャンネル数が2の場合はモノに変換
ch = audio.channels
if ch != CHANNELS:
audio = audio.set_channels(CHANNELS)
print('change to mono audio')
# サンプル幅16ビット(2バイト)に変換
sw = audio.sample_width
if sw != BIT_FORMAT:
audio = audio.set_sample_width(2)
print('change audio bit format')
# サンプリングレートの修正
sr = audio.frame_rate
if sr != SAMPLING_RATE:
audio = audio.set_frame_rate(SAMPLING_RATE)
print('change sr')
return audio
def get_voice_activity_time(audio_tensor):
speech_timestamps = get_speech_timestamps(audio_tensor.float(), vad_model, sampling_rate=SAMPLING_RATE, threshold=0.4)
speech_sound_list = []
for idx,st in enumerate(speech_timestamps):
chunk = audio_tensor[int(st['start']) : int(st['end'])]
speech_sound_list.append(chunk)
return speech_sound_list, speech_timestamps
def main():
receive_data = sys.argv[1]
receive_data = receive_data.replace('\\\\','//')
tl_data = json.loads(receive_data)
# 音声認識結果の保存用変数
result_data = []
result_data.append('speech start time, speech duration, speech 2 txt')
for idx in tl_data.keys():
# オーディオデータフォーマット変換
audio = transform_audio_for_speech_rec(tl_data[idx]['file_path'])
# オーディオデータをNumPy配列に変換する
samples = np.array(audio.get_array_of_samples())
# データをint16のままテンソルに変換
audio_tensor = torch.from_numpy(samples).type(torch.int16)
# davinchi resolveのTL上でクロップされた部分のみ取り出し
audio_start = int(tl_data[idx]['clip_start'] / tl_data[idx]['fps'] * SAMPLING_RATE)
audio_end = int(tl_data[idx]['clip_end'] / tl_data[idx]['fps'] * SAMPLING_RATE)
audio_tensor = audio_tensor[audio_start : audio_end]
# 発話区間のチェック
speech_sound_list, speech_timestamps = get_voice_activity_time(audio_tensor)
for speech_sound, speech_time in zip(speech_sound_list, speech_timestamps):
audio = audio_from_tensor(speech_sound, SAMPLING_RATE)
subtitle = transcribe(recognision_model, audio).text
print(subtitle)
# 発言時間の計算
speech_start_frame = int(tl_data[idx]['tl_position_start']) + int((speech_time['start']/SAMPLING_RATE)*tl_data[idx]['fps'])
speech_duration = (speech_time['end'] - speech_time['start'])/SAMPLING_RATE
result_data.append(str(speech_start_frame) + ',' + str(speech_duration) + ',' + subtitle)
# 結果保存
with open(SAVE_PATH + "voice-recognition-result.txt", "w", encoding='utf-8') as f:
for data in result_data:
f.write(data + "\n")
main()
